
[지디넷코리아]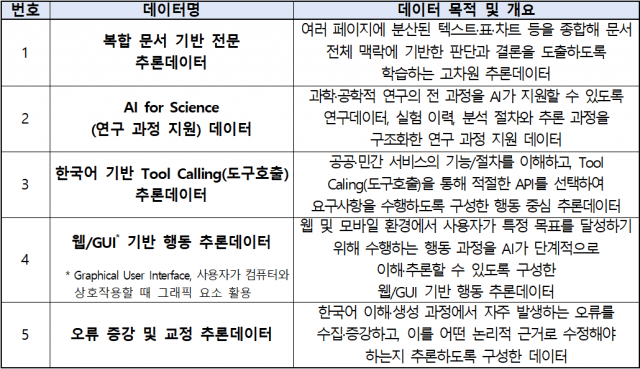
정부가 인공지능(AI) 추론 능력 강화를 위한 학습 데이터 구축에 나섰다.
과학기술정보통신부와 한국지능정보사회진흥원은 2026년 추론데이터 10종 구축 사업 공모를 시작했다고 1일 밝혔다. 총 66억 원 규모로 거대언어모델(LLM)과 제조·로보틱스 분야에서 각각 5개 과제가 추진된다.
이번 사업은 단순 데이터 축적을 넘어 논리적 사고 과정과 인과관계를 포함한 추론형 데이터 확보에 초점 맞췄다. AI 모델 신뢰성을 높이고 실제 산업 환경서 활용 가능한 수준으로 성능을 끌어올릴 방침이다.
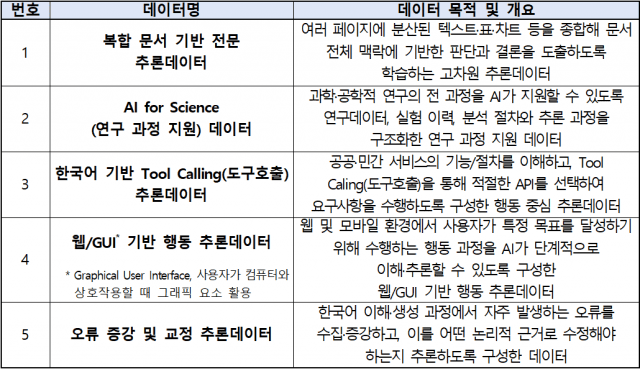
LLM 분야에서는 복잡한 문서 이해와 논리 판단, 도구 활용 등 단계적 문제 해결 과정을 반영한 데이터 구축이 추진된다. 한국어와 국내 사회·문화 맥락을 반영한 데이터 확보도 병행된다. 복합 문서 기반 지식 추론 데이터, 과학 연구 지원 데이터, 한국어 기반 도구 호출 데이터, 웹·GUI 행동 추론 데이터, 오류 교정 추론 데이터 등이 포함된다.
제조·로보틱스 분야에선 실제 산업 현장서 발생하는 문제 기반으로 원인 분석과 해결 방안을 도출하는 데이터 구축이 이뤄진다. 여러 변수 상황에서도 작업을 수정하고 수행할 수 있는 자율 제조 기반 확보가 핵심이다.
관련 과제로는 제조설비 이상 진단 데이터, 표면 결함 분석 데이터, 로봇 작업 실패 복구 데이터, 휴머노이드 행동 생성 시뮬레이션 데이터, 공정 인과성 분석 데이터 등이 해당된다. 구축된 데이터는 향후 ‘AI허브’를 통해 공개돼 기업과 연구기관 스타트업 등이 활용할 수 있도록 제공된다.

업계는 이번 프로젝트 핵심 목적을 AI 기술 신뢰성과 실용성 확보에 두고 있다. 단순히 데이터를 쌓는 단계를 넘어 실제 산업 현장에서 즉시 활용 가능한 수준까지 성능을 끌어올리겠다는 취지라는 설명이다.
최동원 과기정통부 AI인프라정책관은 “생성형 AI 확산으로 고차원적 추론과 맥락 이해가 가능한 학습용 데이터 수요가 증가하고 있다”며 “이번 사업을 통해 실제 산업 현장에서 필요한 맞춤형 추론데이터를 확보해 대한민국 AI 산업의 질적 도약을 적극 지원하겠다”고 밝혔다.