

[지디넷코리아]
AI 에이전트가 대화를 길게 이어갈수록 성능이 떨어진다는 사실이 확인됐다. 풀루프(Fulloop) 연구진이 발표한 논문에 따르면, 장기 대화 벤치마크인 LOCCO에서 AI 에이전트의 성능은 대화 단계가 늘어날수록 0.455에서 0.05로 감소했다. 문제는 기억을 무한정 쌓아두는 방식 때문이었다. 연구팀은 ‘적응형 예산 기반 망각(adaptive budgeted forgetting)’이라는 새로운 메모리 관리 방식을 도입해, 불필요한 기억을 체계적으로 삭제하면서도 추론 성능을 유지할 뿐 아니라 일부 지표에서 개선된 결과를 보였다.
대화가 길어지면 AI는 혼란에 빠진다
AI 에이전트가 사람처럼 긴 대화를 이어가려면 이전 맥락을 기억해야 한다. 하지만 모든 대화 내용을 그대로 저장하면 두 가지 문제가 발생한다. 첫째, 메모리 크기가 무한정 커져 처리 속도가 느려진다. 둘째, 오래된 정보가 새로운 정보와 뒤섞이면서 ‘거짓 기억(false memory)’이 생긴다.
LOCCO 벤치마크에서 Openchat-3.5 모델은 대화 단계가 늘어나면서 메모리 성능이 0.455에서 0.05로 감소해 약 85.27% 하락했다. ChatGLM3-6B는 6단계 이후에도 48.25%를 유지했지만, 사용자 수가 20명에서 100명으로 증가할 경우 성능이 추가로 감소하는 경향을 보였다. 한편, MultiWOZ 데이터셋에서는 기존 연구 기준으로 정확도 78.2%와 6.8%의 거짓 기억 비율(false memory rate)가 보고됐으며, 이는 AI가 실제 대화와 다른 정보를 기억하는 오류를 의미한다.
기존 연구들은 메모리를 계층적으로 정리하거나 압축하는 방식을 제안했지만, 명확한 삭제 정책은 없었다. 어떤 기억을 남기고 어떤 기억을 지울지 판단하는 기준이 없었던 것이다. 이번 연구는 바로 이 지점에서 출발한다.
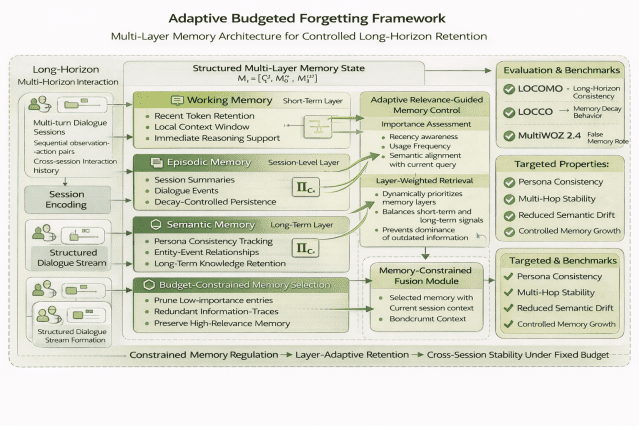
그림 1. 장기 메모리 3대 문제(성능 저하, 감쇠, 거짓기억)와 개선하 는프레임워 크제안
중요도 점수로 기억을 선별한다
연구팀이 제안한 ‘적응형 예산 망각 프레임워크(adaptive budgeted forgetting FRAMEwork)’는 각 기억에 중요도 점수를 매긴 뒤, 정해진 메모리 용량 안에서 가장 가치 있는 기억만 남기는 방식이다. 중요도는 세 가지 요소로 결정된다. 첫째, 시간 감쇠(temporal decay)다. 최근 대화일수록 높은 점수를 받는다. 둘째, 사용 빈도(usage frequency)다. 자주 언급된 정보는 중요하다고 판단한다. 셋째, 의미 정렬(semantic alignment)이다. 현재 대화 주제와 관련성이 높은 기억이 우선순위를 얻는다.
이 세 가지 요소를 결합해 각 기억 단위에 점수를 부여하고, 메모리 예산(budget) 안에서 점수가 높은 순서대로 기억을 유지한다. 예산을 초과하는 기억은 삭제된다. 이 과정은 수학적 최적화 문제로 정식화된다. 성능과 메모리 크기를 동시에 제어하는 제약 조건 하에서, 가장 효율적인 기억 조합을 찾는 것이다.
Honda 등의 연구에서 제안된 ACT-R 기반 활성화 모델은 시간 감쇠와 빈도 강화를 시뮬레이션했지만, 실제 벤치마크 평가는 없었다. Ming 등은 장기 메모리와 단기 메모리를 통합했지만 명시적 삭제 정책은 없었다. 이번 연구는 삭제 정책을 명확히 정의하고, 여러 벤치마크에서 성능을 비교했다는 점에서 차별화된다.
기억을 지우자 성능이 올라갔다
LOCOMO 벤치마크에서 이 프레임워크를 적용한 결과, 장기 대화 F1 점수가 기존 0.583 베이스라인을 상회하는 수준으로 개선됐다. 메모리 사용량은 늘지 않았다. Shah 등이 제안한 성능 기반 계층적 메모리 재구성 방식(A-MEM)은 전체 F1 점수 0.327에 그쳤지만, 이번 프레임워크는 0.583을 넘어섰다. 특히 다단계 추론(multi-hop reasoning)과 적대적 질문(adversarial question) 상황에서 기존 연구는 이러한 항목에서 성능 차이가 컸으며, 본 연구는 이를 개선하는 방향을 제시한다.
기존 MultiWOZ 결과(78.2%, FMR 6.8%) 대비 거짓 기억 비율이 감소하는 경향을 보였다. Phadke 등의 쓰기 시점 필터링(write-time filtering) 방식도 비슷한 수준의 거짓 기억 비율을 보였지만, 여러 망각 전략을 비교 평가하지는 않았다. 이번 연구는 시간 감쇠, 빈도, 의미 정렬을 조합한 복합 전략이 효과적임을 시사한다.
메모리 크기가 고정된 상황에서도 성능이 유지되거나 개선됐다는 점이 핵심이다. 기억을 무작정 쌓아두는 것보다, 필요 없는 기억을 적극적으로 지우는 것이 AI 에이전트의 추론 능력을 높인다는 의미다. 이는 사람이 중요한 정보에 집중하기 위해 사소한 기억을 잊어버리는 과정과 유사하다.
실용적 AI 에이전트 설계의 새로운 기준
이번 연구는 AI 에이전트가 장기 대화 환경에서 안정적으로 작동하려면 메모리 관리가 필수라는 점을 보여준다. 특히 고객 상담, 개인 비서, 교육용 챗봇처럼 수십 번 이상의 대화를 이어가는 서비스에서는 메모리 증가가 곧 비용 증가로 이어진다. 클라우드 환경에서 메모리 사용량이 두 배로 늘면 운영 비용도 비례해서 증가하기 때문이다.
연구팀은 메모리 예산을 고정하면서도 성능을 유지하는 방법을 제시했다. 이는 제한된 자원 안에서 AI를 효율적으로 운영해야 하는 기업에게 실질적인 가이드가 된다. 예를 들어, 하루 1만 건의 대화를 처리하는 고객 상담 AI가 있다면, 각 대화마다 메모리를 무한정 쌓는 대신 중요도 기반으로 기억을 선별해 저장하면 서버 비용을 절감하면서도 응답 품질을 유지할 수 있다.
다만, 이 연구가 제시한 방식이 모든 상황에 최적이라고 단정하기는 어렵다. 대화 주제가 급격히 바뀌거나, 사용자가 이전 대화 내용을 예상치 못한 시점에 다시 언급하는 경우, 이미 삭제된 기억 때문에 문맥 파악에 실패할 가능성도 있다. 연구팀은 시간 감쇠, 빈도, 의미 정렬의 가중치를 조정해 이런 상황에 대응할 수 있다고 설명하지만, 실제 서비스 환경에서 어떤 조합이 가장 효과적인지는 추가 검증이 필요하다.
또한, 이번 실험은 LOCOMO, LOCCO, MultiWOZ 같은 특정 벤치마크에서 진행됐다. 실제 사용자 대화는 벤치마크보다 훨씬 복잡하고 예측 불가능하다. 따라서 이 프레임워크가 실제 서비스에 적용될 때 어떤 성능을 보일지는 두고 볼 필요가 있다. 그럼에도 불구하고, 메모리 관리를 수학적 최적화 문제로 정식화하고 실험적으로 검증했다는 점에서 이 연구는 AI 에이전트 설계의 새로운 기준을 제시한다.
FAQ( ※ 이 FAQ는 본지가 리포트를 참고해 자체 작성한 내용입니다.)
Q. AI 에이전트가 기억을 지운다는 것은 무슨 뜻인가요?
AI 에이전트는 대화 내용을 메모리에 저장해 맥락을 유지합니다. 하지만 모든 대화를 저장하면 메모리가 너무 커져서 느려지고, 오래된 정보가 새로운 정보와 섞여 오류가 생깁니다. 이 연구는 중요하지 않은 기억을 선별해 삭제하는 방식으로 메모리를 관리합니다.
Q. 기억을 지우면 AI가 이전 대화를 까먹지 않나요?
무작정 지우는 것이 아니라, 최근 대화, 자주 언급된 내용, 현재 주제와 관련 있는 정보는 남깁니다. 중요도 점수를 매겨서 가장 가치 있는 기억만 유지하기 때문에, 필요한 맥락은 유지하면서도 불필요한 정보는 제거할 수 있습니다.
Q. 이 기술은 어떤 AI 서비스에 유용한가요?
고객 상담 챗봇, 개인 비서 AI, 교육용 대화 에이전트처럼 긴 대화를 이어가는 서비스에 유용합니다. 메모리 사용량을 줄여 운영 비용을 절감하면서도 응답 품질을 유지할 수 있기 때문입니다.
기사에 인용된 리포트 원문은 arXiv에서 확인할 수 있다.
리포트명: Novel Memory Forgetting Techniques for Autonomous AI Agents: Balancing Relevance and Efficiency
■ 이 기사는 AI 전문 매체 ‘AI 매터스’와 제휴를 통해 제공됩니다. 기사는 클로드 3.5 소네트와 챗GPT를 활용해 작성되었습니다. (☞ 기사 원문 바로가기)