
[지디넷코리아]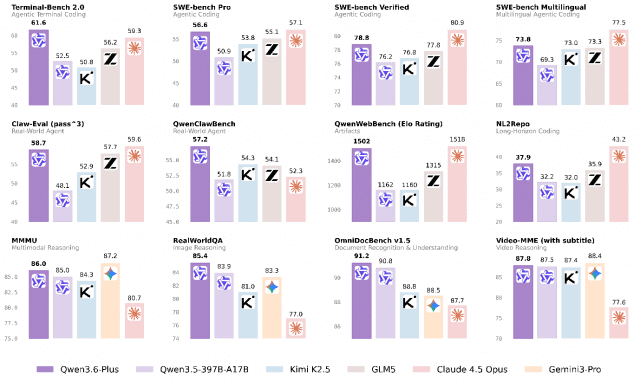
알리바바가 자율 코딩 에이전트와 옴니모달 인공지능(AI) 모델을 동시에 내놓으며 AI 모델 경쟁에 속도를 높이고 있다.
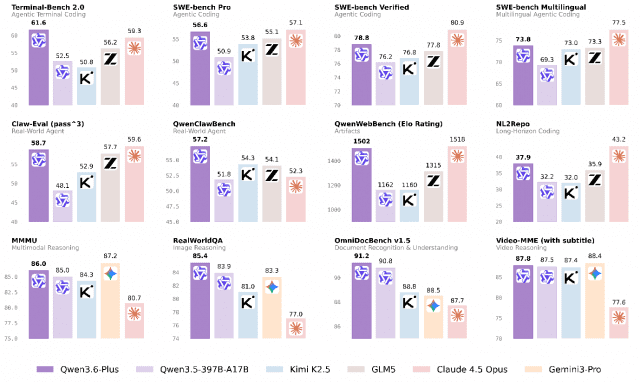
알리바바 그룹은 에이전틱 코딩 특화 모델 ‘큐원3.6-플러스(Qwen3.6-Plus)’와 텍스트·음성·이미지·영상을 통합 처리하는 옴니모달 모델 ‘큐원3.5-옴니(Qwen3.5-Omni)’를 6일 선보였다. 두 모델은 에이전틱 실행 역량과 멀티모달 통합 처리 역량을 각각 강화하는 투트랙 전략으로 설계됐다.
큐원3.6-플러스는 저장소 단위의 엔지니어링 작업과 실제 시각 환경 기반 문제 해결을 자율 수행하도록 설계됐다. 인식·추론·행동을 단일 워크플로로 연결하는 ‘능력 루프’ 구조를 핵심으로, 초기 코드 구상부터 테스트·반복 개선·최종 정제까지 전 과정을 일관되게 처리한다.
기본 100만 토큰 컨텍스트 창을 지원하며, 사용자 인터페이스(UI) 스크린샷이나 손그림 와이어프레임을 해석해 동작 가능한 프론트엔드 코드를 생성하는 시각적 코딩 기능도 갖췄다. 모델 스튜디오와 큐원 챗에서 사용할 수 있고 클로드 코드·클라인 등 외부 코딩 도구와도 호환된다.
큐원3.5-옴니는 텍스트·음성·이미지·영상을 단일 모델에서 처리하는 옴니모달 AI로, 플러스·플래시·라이트 세 버전 모두 최대 256K 토큰 컨텍스트를 지원한다. 하이브리드 어텐션 혼합전문가 아키텍처 기반으로 10시간 이상의 연속 오디오를 처리할 수 있다. 음성 인식은 113개 언어·방언, 음성 생성은 36개 언어·방언을 지원한다. 최상위 모델인 큐원3.5-옴니-플러스는 200개 이상의 벤치마크에서 음성 이해·추론·다국어 번역 등 영역에서 구글의 제미나이 3.1 프로보다 우수한 성능을 기록했다고 회사 측은 밝혔다.
손으로 그린 스케치를 보여주고 기능을 음성으로 설명하면 앱·웹사이트·미니게임용 UI를 자동 생성하는 ‘오디오-비주얼 바이브 코딩’ 기능도 눈길을 끈다. 아리아(ARIA·Adaptive Rate Interleave Alignment) 기술을 적용해 스트리밍 상호작용에서 음성 합성의 안정성과 자연스러움도 끌어올렸다. 라이브 스트리밍, 지능형 음성 비서, 게임·엔터테인먼트용 영상 자막 생성 등 다양한 실사용 환경을 겨냥했다.
알리바바 측은 “이번 두 최신 AI 모델 공개로 에이전틱 코딩과 멀티모달 인식·추론 역량을 강화했다”며 “텍스트·음성·이미지·영상의 다양한 데이터 유형에 걸친 인식·추론·생성도 하나로 통합해, 오프라인 지능 처리와 실시간 상호작용 역량을 끌어올렸다”고 강조했다.