

[지디넷코리아]
북경대와 둥화대, 화난이공대 공동 연구진이 3월 23일 발표한 유니모션(UniMotion) 논문은 AI가 사람의 동작, 이미지, 텍스트를 하나의 ‘언어’처럼 자유롭게 읽고 쓸 수 있게 만든 첫 사례다. “앉았다 일어나”라는 말을 듣고 3D 동작을 만들고, 반대로 춤추는 영상을 보고 “발을 앞으로 내딛고 팔을 흔든다”는 설명을 자동으로 써내는 일이 같은 시스템 안에서 동시에 가능해졌다는 뜻이다.
기존 AI는 움직임을 ‘단어’로 쪼갰다가 잃어버렸다
지금까지 AI는 사람의 움직임을 다룰 때 마치 영화 필름을 사진으로 찢어 보관하듯 ‘단어’로 바꿔 저장했다. 모션GPT 같은 기존 기술은 VQ-VAE라는 방식으로 동작을 512개 코드북의 조합으로 쪼갰다. 문제는 이 과정에서 어깨를 얼마나 들어 올렸는지, 발끝이 정확히 어디를 향했는지 같은 미세한 정보가 증발한다는 점이었다. 연구진 실험 결과 VQ-VAE 방식은 손목 위치 오차가 평균 212.9mm에 달했다. 성인 손바닥 너비를 두 번 벌려놓은 정도다.
유니모션은 이 문제를 ‘연속 공간’으로 해결했다. 동작을 코드로 자르지 않고 수학적 좌표 그대로 보존하는 CMA-VAE 구조를 만든 것이다. 같은 조건에서 손목 오차는 43.8mm로 떨어졌다. 5분의 1 수준이다. 더 중요한 건 시간 흐름이 자연스럽게 이어진다는 점이다. 기존 방식은 프레임마다 코드가 바뀌면서 움직임이 뚝뚝 끊기는 ‘지터’ 현상이 생겼지만, 유니모션은 실제 사람의 가속도 패턴과 거의 동일한 부드러움을 보였다.
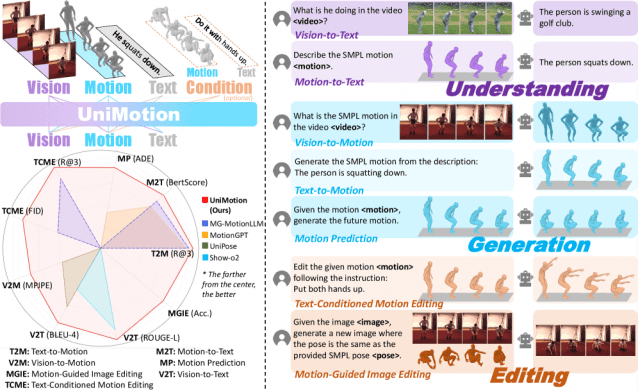
그림 1. 움직임·텍스트·영상 세 가지를 하나의 모델로 처리하는 유니모션(UniMotion)이 기존 모델들이 일부만 지원하던 7가지 과제를 최초로 전부 수행하며 성능도 앞섰다.
영상 없이도 ‘눈으로 본 것처럼’ 학습하는 구조
연구진은 여기서 한 발 더 나갔다. 평소엔 동작 데이터만 보지만, 훈련 중에는 영상과 동작을 함께 보는 ‘이중 인코더’ 방식(DPA)을 설계했다. 비유하자면 학생이 교과서(동작)만 보고 공부하지만, 선생님이 옆에서 그림(영상)을 보며 설명해주는 방식이다. 훈련이 끝나면 선생님은 떠나고 학생 혼자 문제를 푸는데, 이미 시각 정보의 핵심이 머릿속에 남아 있다.
실제로 DPA를 제거하자 텍스트→동작 생성 정확도(R@3)가 0.841에서 0.818로, 동작 편집 정확도는 84.94%에서 80.35%로 떨어졌다. 영상 없이도 “몸의 균형은 어때야 하는가” “팔다리 비율은 자연스러운가” 같은 시각적 직관이 내재화됐다는 증거다.
스스로 복습하며 구조를 익히는 ‘자가 정렬’ 단계
연구진은 본격 훈련 전 AI에게 ‘자가 복습’ 시간을 줬다. LRA(잠재 복원 정렬)라는 단계에서 시스템은 자신이 인코딩한 동작 정보를 노이즈에서 다시 복원하는 연습만 8만 스텝 반복한다. 텍스트 설명 같은 애매한 힌트 없이 “이 좌표값이 주어지면 원래 동작은 이거였다”는 명확한 정답만으로 뼈대를 다지는 것이다.
이 단계를 건너뛰면 어떻게 될까. 텍스트→동작 점수는 0.801, 동작 예측 오차는 3.777mm로 치솟았다. 반대로 자가 정렬을 거치면 0.841과 3.172mm로 안정된다. 마치 악보를 읽기 전에 스케일 연습부터 하는 음악가처럼, AI도 구조를 먼저 익혀야 복잡한 과제를 안정적으로 처리한다.
7가지 일을 한 몸으로 처리하는 통합 설계
유니모션의 진짜 강점은 범용성이다. 텍스트→동작, 동작→텍스트, 동작 예측, 동작 편집, 영상→동작, 영상→텍스트, 동작 기반 이미지 편집까지 총 7개 작업을 단일 모델로 처리한다. 기존엔 작업마다 별도 모델이 필요했다. 모션GPT는 텍스트↔동작만, 유니포즈는 정지 자세↔이미지만 다뤘다.
통합의 핵심은 ‘듀얼 패스 임베더’다. 동작 정보를 두 갈래로 처리하는데, 한쪽은 의미(Semantic)를 추출하고 다른 쪽은 세부 좌표(Generation)를 보존한다. 마치 책을 읽을 때 줄거리와 문장 표현을 동시에 기억하는 것과 같다. 동작 편집 과제에서 이 구조는 결정적이다. “양손을 위로”라는 명령(의미)을 이해하면서도 원본 동작의 걸음 폭이나 어깨 각도(세부)는 그대로 유지해야 하기 때문이다.
전문 모델보다 정확하고, 범용 모델보다 세밀하다
휴먼ML3D 데이터셋 텍스트→동작 생성에서 유니모션은 R@3 점수 0.841로 1위를 기록했다. 단일 과제 전문 모델 MoMask(0.807)를 제쳤다. 동작→텍스트 설명에선 BertScore 41.2로 기존 최고(36.7)를 크게 앞섰다. 동작 예측 오차는 3.172mm로 모션GPT(4.745mm) 대비 33% 개선됐다.
영상→동작 변환에선 MPJPE 75.0으로 같은 통합 모델인 유니포즈(81.8)를 8.3% 앞섰다. 전문 모델(TokenHMR 52.4)과는 여전히 격차가 있지만, 7개 작업을 동시 지원하는 모델 중에선 독보적이다. 동작 기반 이미지 편집에선 모션 정확도 67%로 기존 2단계 방식(50~59%)을 압도했다.
AI 동작 이해는 이제 ‘읽기·쓰기·번역’을 모두 아는 단계
유니모션이 보여준 건 단순히 성능 향상이 아니다. 동작을 ‘언어’처럼 다루는 패러다임 전환이다. 기존 AI는 영어만, 또는 불어만 구사했다면, 이젠 영·불·독을 넘나들며 통역까지 하는 셈이다. 연속 공간 표현, 시각 정보 증류, 자가 정렬 사전 훈련이라는 세 기둥이 이 전환을 가능하게 했다.
다만 몇 가지는 두고 봐야 한다. 첫째, 훈련 데이터 대부분이 실내 촬영 환경(Human3.6M)이라 야외 복잡한 상황에서 시각 정렬이 얼마나 유지될지 미지수다. 둘째, 15억 파라미터 모델이라 실시간 모바일 구동은 아직 무리다. 셋째, 논문은 단일 프레임→동작 복원을 주로 다뤘는데, 다중 프레임 영상에서 시간 추론을 어떻게 강화할지는 후속 과제로 남았다.
그럼에도 이 연구가 여는 가능성은 크다. 게임 캐릭터가 자연어 지시만으로 즉석 애니메이션을 만들고, 재활 치료사가 환자 동작을 촬영하면 AI가 자동으로 교정 가이드를 텍스트로 출력하는 미래가 구체화되고 있다.
FAQ( ※ 이 FAQ는 본지가 리포트를 참고해 자체 작성한 내용입니다.)
Q. 유니모션이 기존 모션GPT와 다른 핵심 차이는 무엇인가요?모션GPT는 동작을 512개 코드로 쪼개 저장(VQ-VAE)하지만 유니모션은 좌표를 연속값으로 유지(CMA-VAE)합니다. 덕분에 손목 위치 오차가 212.9mm에서 43.8mm로 줄고, 시간 흐름도 끊김 없이 자연스러워집니다.
Q. ‘듀얼 패스 임베더’는 왜 두 갈래로 나뉘나요?한쪽(Semantic)은 “앉는다”는 의미를, 다른 쪽(Generation)은 무릎 각도 같은 세부를 담습니다. 동작 편집 시 명령은 이해하되 원본 디테일은 보존해야 하므로 둘 다 필요합니다.
Q. LRA 자가 정렬 단계는 왜 필요한가요?텍스트 설명은 “걷는다”처럼 추상적이라 학습 신호가 모호합니다. 반면 동작 좌표는 명확한 정답이므로, 먼저 이걸로 뼈대를 다진 뒤 텍스트 학습을 하면 성능이 크게 오릅니다(R@3 0.801→0.841).
기사에 인용된 리포트 원문은 arXiv에서 확인할 수 있다.
리포트명: UniMotion: A Unified FRAMEwork for Motion-Text-Vision Understanding and Generation
■ 이 기사는 AI 전문 매체 ‘AI 매터스’와 제휴를 통해 제공됩니다. 기사는 클로드 3.5 소네트와 챗GPT를 활용해 작성되었습니다. (☞ 기사 원문 바로가기)