[지디넷코리아]
가현욱 KAIST 융합인재학부 재활인공지능연구실 교수가 13일 시각 장애인을 위한 점자 번역 엔진을 공개하고, 이를 사회에 무상 환원하겠다고 선언했다.
KAIST는 가현욱 교수 연구팀이 일반 글자(묵자)를 시각장애인이 읽을 수 있는 점자로 변환하는 점역 기술을 고도화한 차세대 점자 번역 엔진 ‘케이-브레일(K-Braille)’을 개발하고 대규모 성능 검증을 완료했다고 밝혔다.
가현욱 교수는 지디넷코리아와의 전화통화에서 “성능평가까지완료돼 있다. 포팅 작업 등 요구사항 등도 일부 충족시킬 부분이 있지만, 기술이전에 적합하다고 판단이 드는 협력자들 요청이 온다면 다음 주라도 오픈 및 무료 서비스가 가능할 것”이라고 말했다.
가 교수는 “지속 가능성이 확보되지 않은 무책임한 오픈 소스화는 곤란하다”며 “오픈, 서비스에 들어가도라도 이용자가 비용을 부담하게 해선 안될 것”이라고 이술이전 사전 요건을 명확하게 정리했다.
연구팀은 이 엔진을 ‘포용적 AI’기술로 사회에 전면 무상으로 환원할 계획이다. 다만, 기술의 파편화를 막고 지속 가능한 생태계를 유지하기 위해 무분별한 소프트웨어 오픈소스화보다는 공공기관, 교육청, 점자 도서관, 그리고 보조기기 제조사 등 ‘책임 있는 기술 활용 주체’들과의 공식적인 기술 이전 및 제휴망 구축을 원하고 있다.
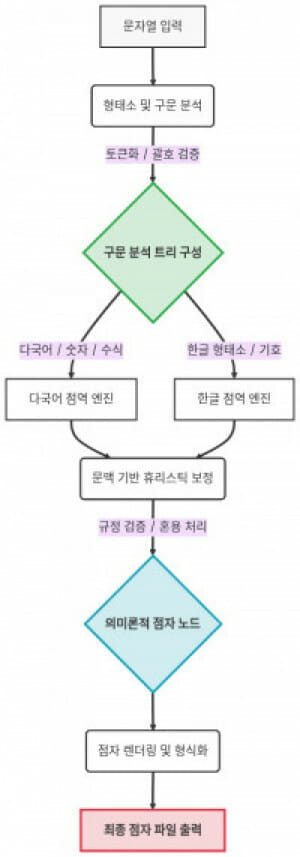
이번에 선보인 점역 기술은 책, 문서, 웹페이지 등 일반 문자로 작성된 정보를 점자 체계에 맞게 변환하는 것으로 시각장애인의 정보 접근을 위해 필수다. 그러나 한국어 점자 규정은 띄어쓰기, 기호, 외국어 표기 등 다양한 예외 규칙이 존재해 정확한 자동 점역이 쉽지 않다.
케이-브레일의 가장 큰 특징은 문장을 이해하는 점역 시스템이라는 점이다. 기존 점역 프로그램이 문자나 기호를 단순히 바꾸는 치환 방식이라면, 케이-브레일은 형태소 분석과 문장 구조 분석(AST)을 통해 맥락을 이해하고, 점자로 변환한다.
외국어와 한글이 혼용된 문장, 복잡한 기호 조합, 단위 표기 등 개정된 점자 규정의 다양한 예외 상황을 보다 정확하게 처리한다.
연구팀은 기술의 정확도를 확인하기 위해 국립국어원이 구축한 국내 최대 규모 점자 데이터셋인 ‘묵자-점자 병렬 말뭉치(NLPAK)’를 활용했다. 이 데이터에는 일반 글자와 점자가 짝을 이루는 문장들이 함께 정리돼 있다.
연구팀은 여기서 1만 7,943개 문장을 추출해 케이-브레일 점역 결과가 실제 점자와 얼마나 일치하는지 전수 평가를 진행했다. 이 결과 점자 규정을 실제로 얼마나 정확하게 따르는지를 나타내는 ‘실질 점역 규정 준수율’은 100.0%, 점자 문장 구조가 정답과 얼마나 비슷한지를 보여주는 점역 형태소 구조 유사도도 평균 99.81%를 기록했다.
또한 국립국어원 공식 점역 프로그램 ‘점사랑 6.3.5.8’과 동일 문장 세트를 이용한 비교 검증에서도 케이-브레일이 훨씬 더 높은 점역 일치율을 나타냈다.
연구팀은 향후 기존 점자 파일 형식(.brf)의 한계를 넘어 새로운 점자 파일 형식을 만들고, 그 파일을 작성·읽기·공유할 수 있는 소프트웨어와 장치 환경을 함께 만드는 차세대 전자 점자 파일 포맷(.brfx) 생태계도 구축할 계획이다.
한편 가현욱 교수는 최근 KAIST 발전기금 10억 원을 기탁한 정인서 융합인재학부 재학생(학사과정)이자 스타트업 엠피에이지(MPAG) 대표 지도교수다.